本案例研究对claude 3.5 sonnet和gpt-4o两种人工智能模型进行了深入比较,涵盖性能、定价和具体应用场景,并结合社区反馈、基准测试和实际使用经验。
Claude 3.5 Sonnet:智能且人性化
Claude 3.5 Sonnet是什么?
Claude 3.5 Sonnet是Anthropic公司开发的一款人工智能助手,强调道德性和人性化交互。它基于大型语言模型,由前OpenAI成员参与研发。“宪法人工智能”方法旨在使其更符合人类价值观。
主要特点:
Claude 3.5 Sonnet被认为是Claude 3.5系列中最强大的模型,擅长逻辑推理和创意任务。 适用于总结、研究、写作和决策等任务。 提供免费版本,但功能有限;用户可升级到付费计划以获得更多功能。使用感受:
Claude 3.5 Sonnet在需要人性化交互和创意解决方案的领域表现出色。例如,在个人测试中,它对提示的回应富有创造力且独具特色。
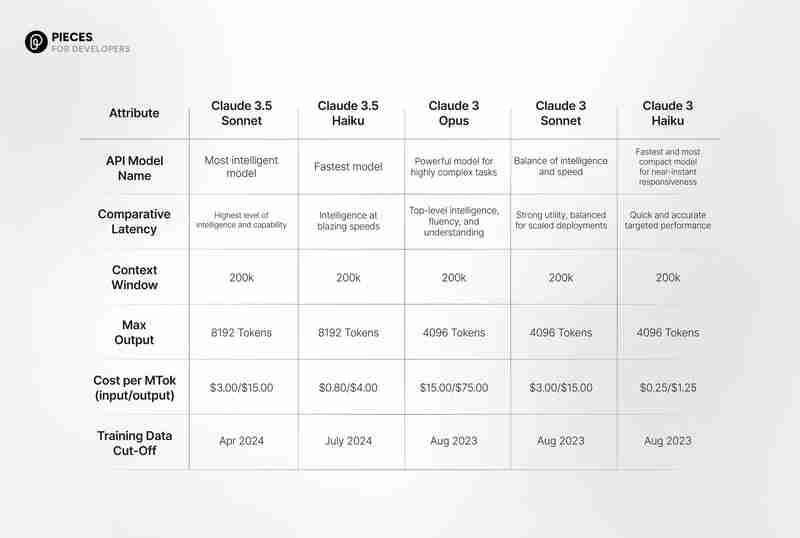
然而,在数学问题求解和复杂推理等专业领域略逊一筹,准确率低于GPT-4o。

GPT-4o:多功能且高效
GPT-4o是什么?
GPT-4o是OpenAI推出的最新人工智能模型,能够处理多种类型的输入(文本、音频、图像和视频)。其中的“o”代表“omni”,强调其多模态能力。该模型经过训练,可处理复杂任务,从高级推理到跨领域问题求解。

使用感受:
在处理复杂任务方面,GPT-4o的性能优于许多竞争对手。基准测试显示,GPT-4o在数学问题求解、推理和速度方面得分更高。对于需要快速响应和多输入输出功能的用户而言尤为适用。
模型基准测试:主要对比
1. 研究生水平推理(GPQA、钻石基准):
GPQA基准评估人工智能处理研究生水平推理的能力。
Claude 3.5 Sonnet: 零样本CoT任务准确率达59.4%。 GPT-4o: 零样本CoT任务准确率达53.6%。结论: Claude 3.5 Sonnet在研究生水平推理方面表现更佳。
2. 数学问题求解(数学基准):
在解决复杂的数学问题时,GPT-4o表现更好。
Claude 3.5 Sonnet: 零样本CoT准确率为71.1%。 GPT-4o: 零样本CoT准确率为76.6%。结论: GPT-4o更适合处理数学密集型任务。
3. 延迟和速度:
速度和延迟对于实时应用至关重要。
GPT-4o: 平均延迟比Claude 3.5 Sonnet快24%。 Claude 3.5 Sonnet: 稍慢,首个token生成时间较长,输出token数量较少。结论: GPT-4o在速度和响应能力方面更胜一筹。
4. 上下文理解准确性:
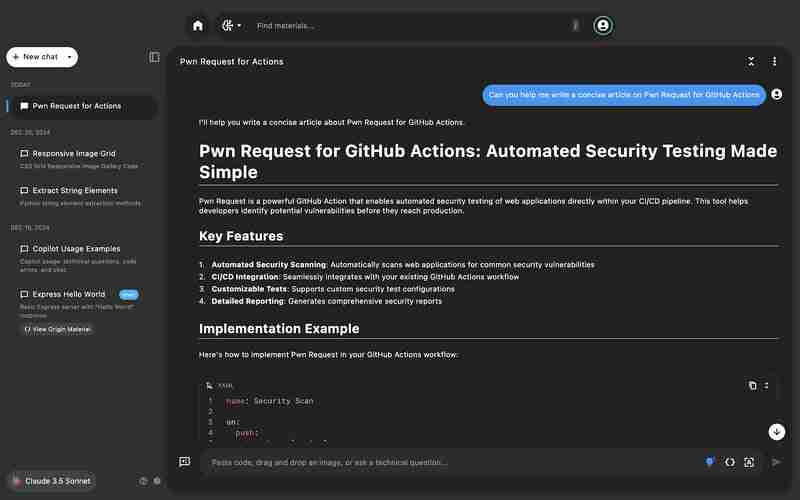
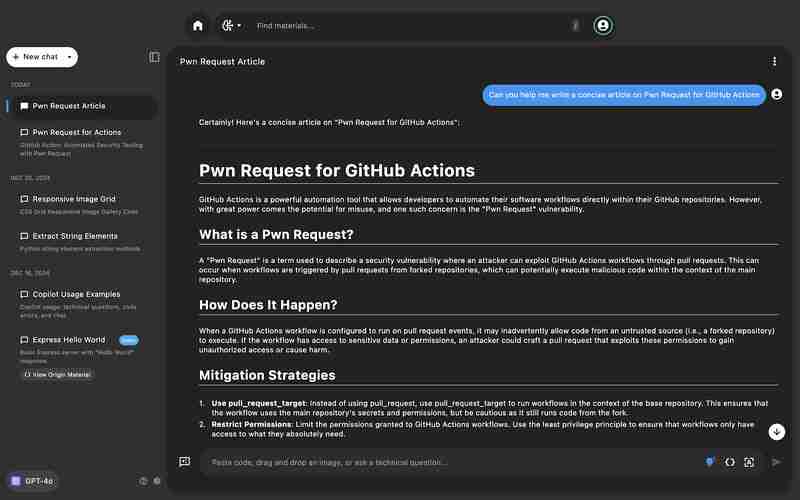
为了测试上下文理解准确性,比较了模型对“Pwn Request for GitHub Actions”提示的响应能力。
Claude 3.5 Sonnet: 提供了错误的响应。 GPT-4o: 正确地将其识别为漏洞。结论: GPT-4o在提供上下文相关的答案方面更准确。
定价对比
Claude 3.5 Sonnet:
免费版本有使用限制(约10个提示)。 付费API定价:每百万代币输入3美元,每百万代币输出15美元。 Claude Pro计划:每月18美元,提供附加功能。GPT-4o(通过OpenAI):
ChatGPT Plus:每月20美元,提供完全访问权限。 API定价:每百万输入代币2.50美元。结论:
Claude在基础使用成本方面更灵活,而GPT-4o更适合需要高性能和快速输出的专业人士。
总结:选择哪个模型?
选择Claude 3.5 Sonnet,如果: 您需要一个能够提供创造性和人性化回应的人工智能。它非常适合需要同理心、对话和逻辑问题解决的任务,例如写作、头脑风暴和内容总结。 选择GPT-4o,如果: 您需要高性能AI来执行涉及数学、编程和高级推理的复杂任务。对于处理复杂、多模态任务和实时应用的专业人士而言,GPT-4o更为强大。全文阅读:[此处添加全文链接]
以上就是克劳德·十四行诗 vs GPT-4o的详细内容,更多请关注php中文网其它相关文章!